Trevor Chow
I am exploring how ML systems can advance frontier domains in economically transformative ways.
I write and invest. On weekends, I skydive, ski, cook, watch F1 (and Grey’s), and listen to Taylor Swift.
Previously, I founded a ML infra company (backed by YC and BCV), hazily researched, and traded options.
(Scrollable) Bookshelf













Feeling the AGI
RL Turns Smart Models Into Useful Products
Diffusing the AGI across the economy requires the co-design of product deployment with model research.
Pre-Training Isn't Dead, It's Just Resting
Pre-training scaling laws haven’t bent, but the marginal dollar has moved to RL. It’ll come back and the OOMs will grow.
VC Investments in AI Labs are Betting Against AGI
Scaling laws reward the consolidation of AI labs, but investors are diversifying anyways. This indefinite optimism is a mistake.
You Can Find the Best LLM Output Without Labels
By taking advantage of a weak supervision-inspired approach, we can find the best LLM output at inference time, without needing ground truth labels. Accepted to NeurIPS ‘24.
Reasoning Will Speed Up AI Research
o1 is a bigger deal than ChatGPT: it marks the start of the reasoning paradigm. Decades of progress will occur in months.
Pre-Training is About Data Above All Else
The three key insights from pre-training LLMs in the last 4 years all point to the importance of data.
Polysemantic Neurons Can Occur Incidentally
Polysemantic neurons are an obstacle to interpreting AI. Even in over-parameterised models, they can arise incidentally. Accepted to BGPT & Re-Align @ ICLR ‘24.
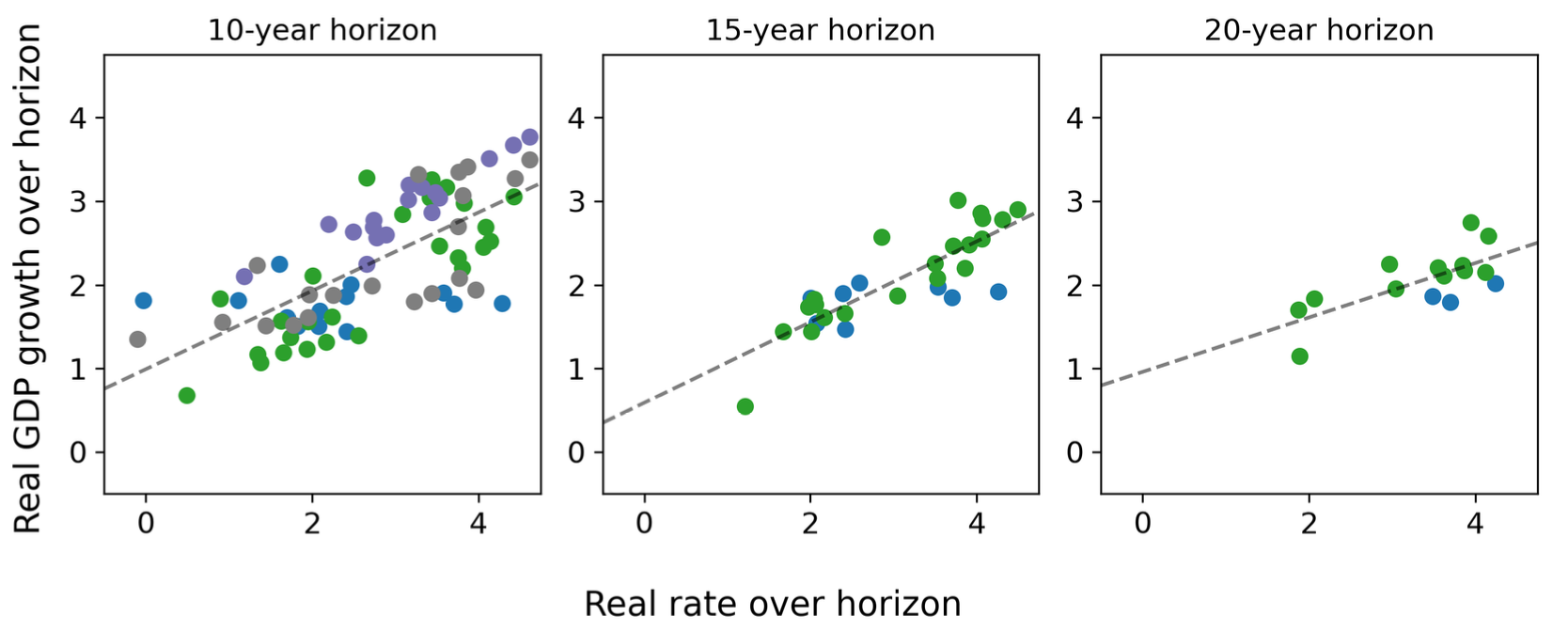
Bond Markets Aren't Predicting AGI
The arrival of AGI means an increase in real interest rates. Rates are still low: markets are not expecting AGI in the next 30 years! Accepted to Oxford GPR ‘23. Seen in The Economist (x2), FT (x2), BBG, Vox, AEI (x2) etc.
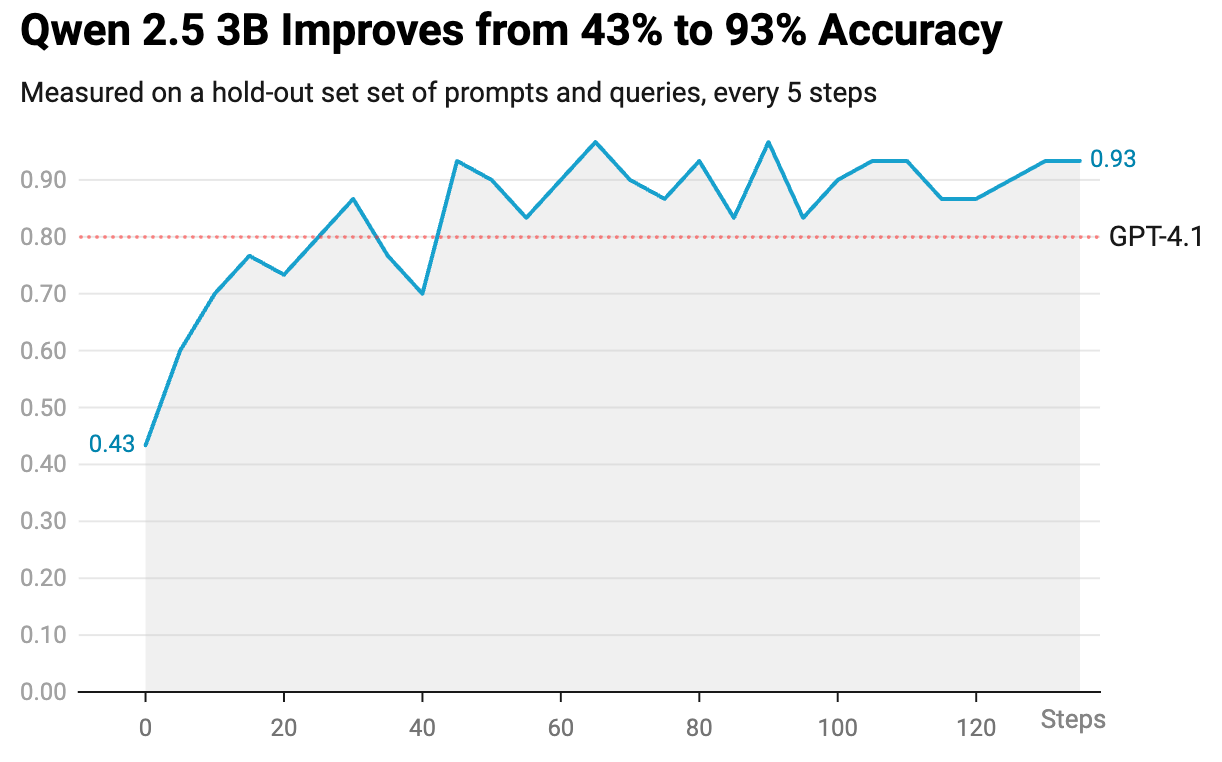
RL Turns Smart Models Into Useful Products
Diffusing the AGI across the economy requires the co-design of product deployment with model research.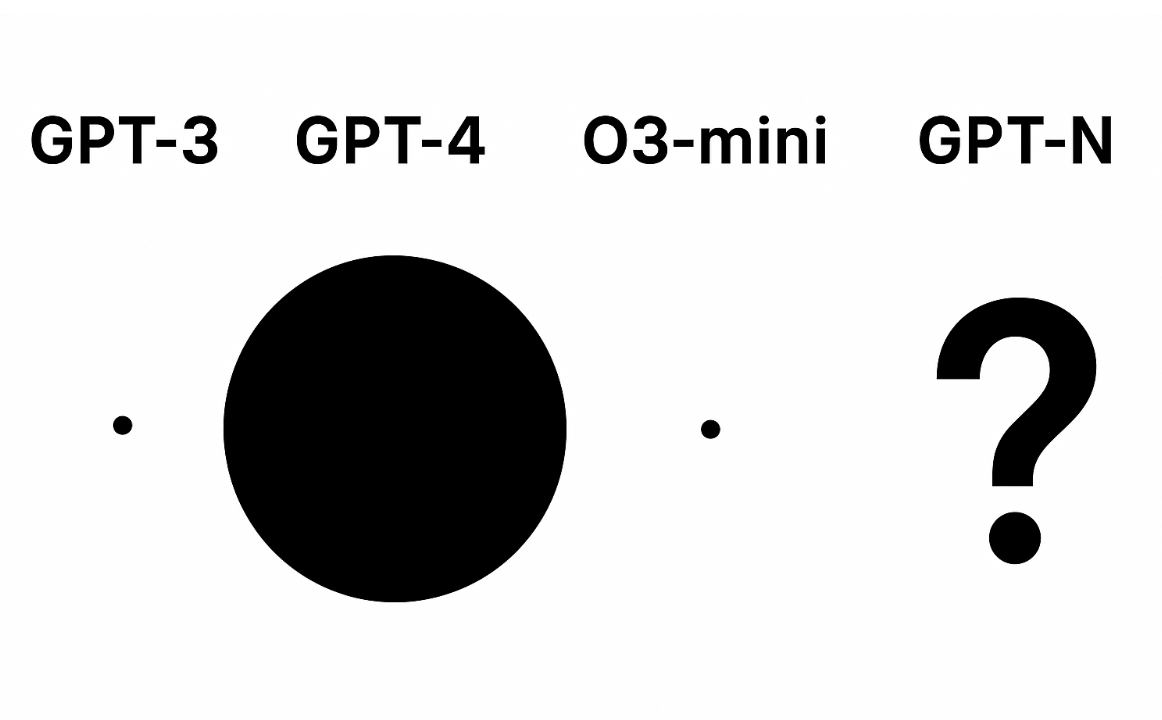
Pre-Training Isn't Dead, It's Just Resting
Pre-training scaling laws haven’t bent, but the marginal dollar has moved to RL. It’ll come back and the OOMs will grow.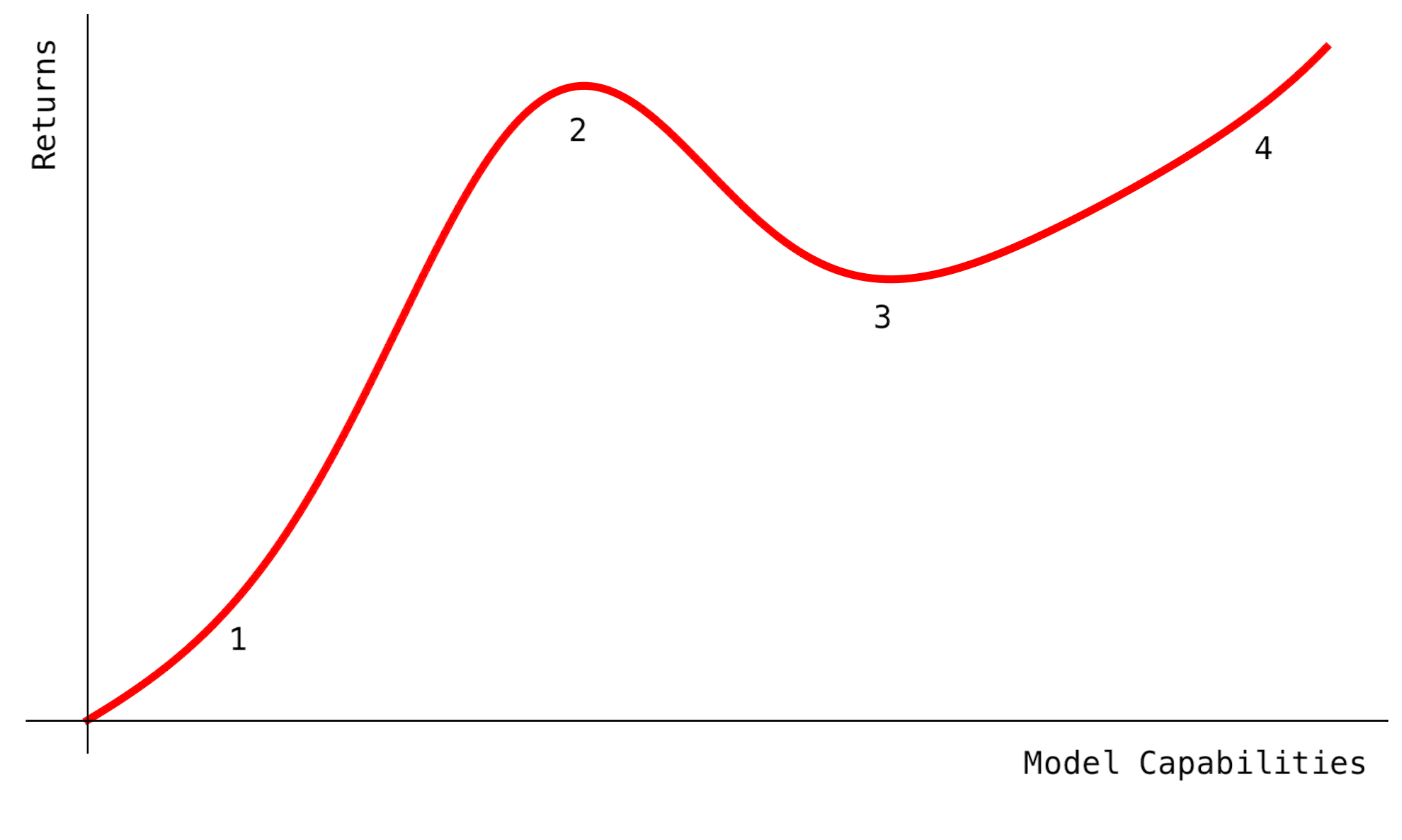
VC Investments in AI Labs are Betting Against AGI
Scaling laws reward the consolidation of AI labs, but investors are diversifying anyways. This indefinite optimism is a mistake.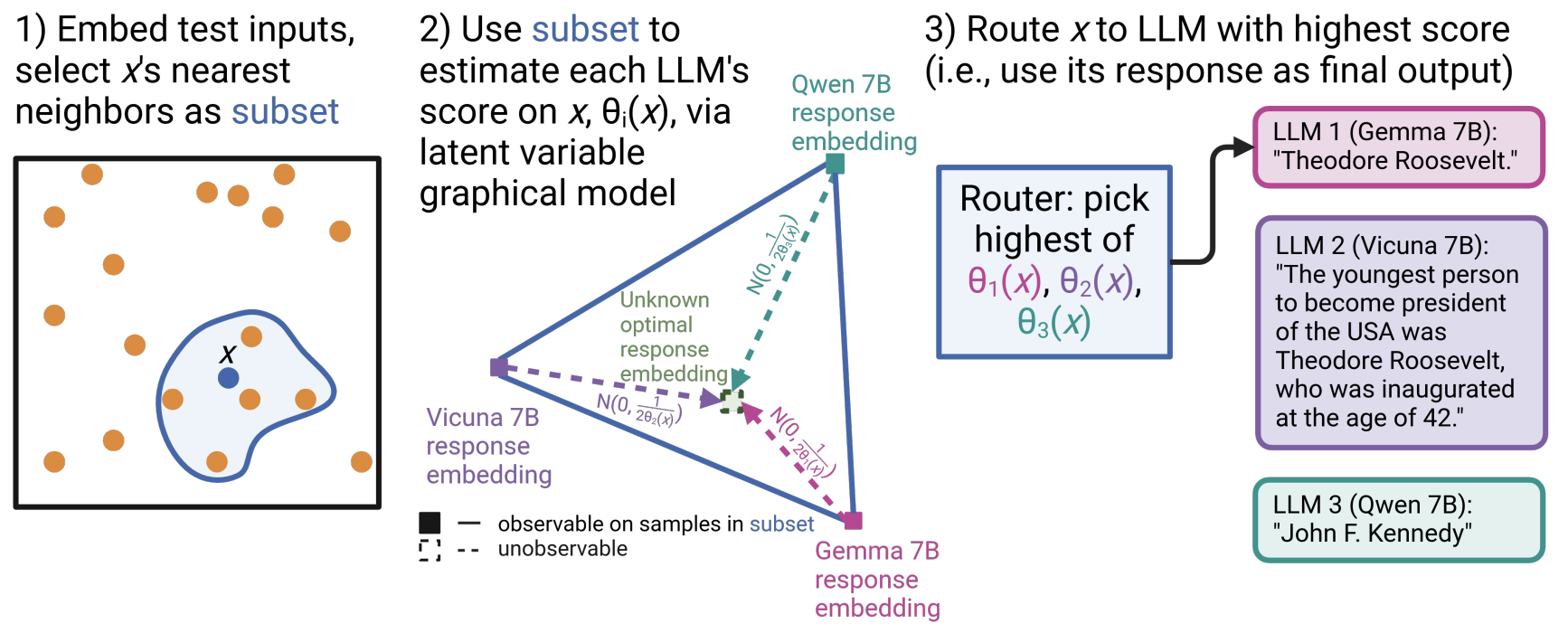
You Can Find the Best LLM Output Without Labels
By taking advantage of a weak supervision-inspired approach, we can find the best LLM output at inference time, without needing ground truth labels. Accepted to NeurIPS ‘24.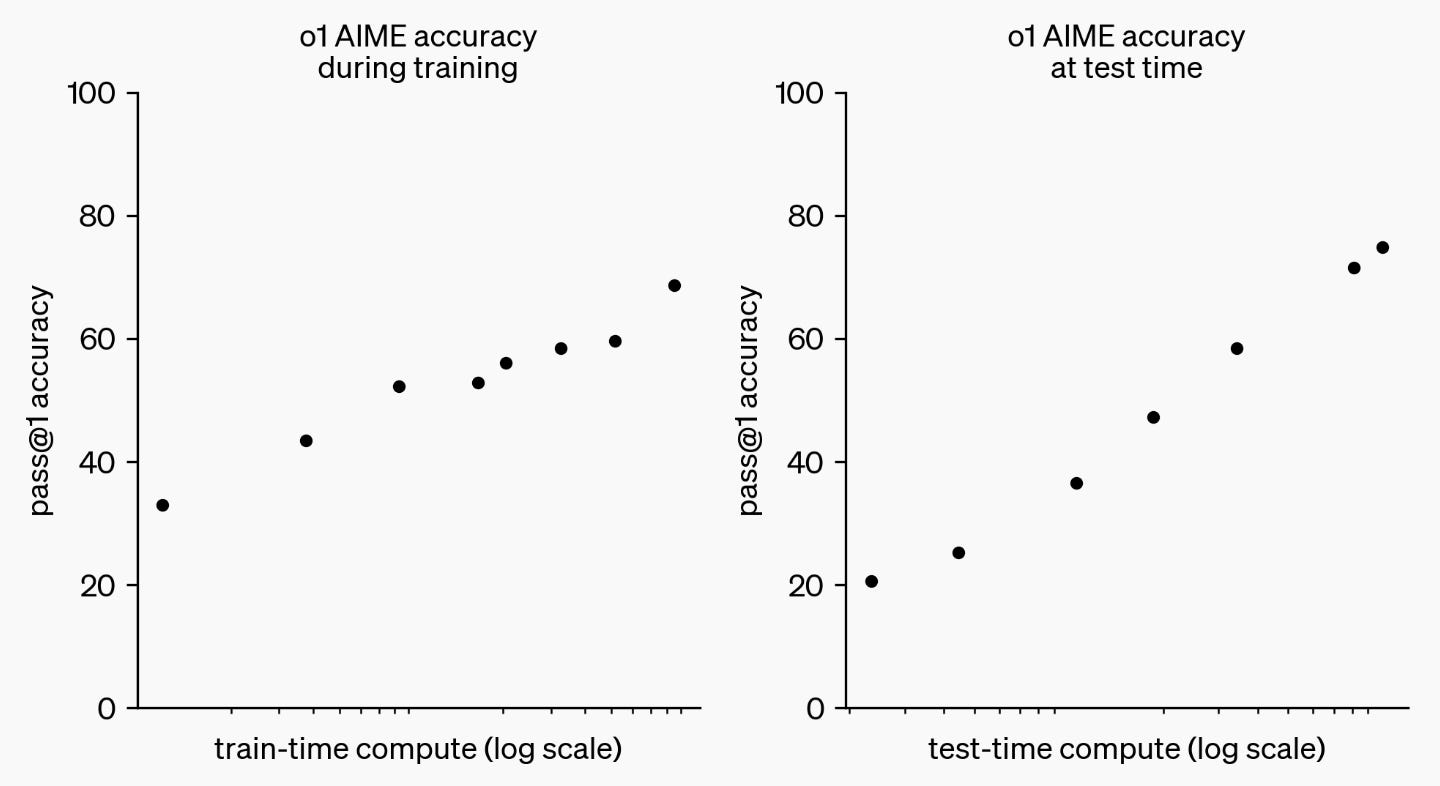
Reasoning Will Speed Up AI Research
o1 is a bigger deal than ChatGPT: it marks the start of the reasoning paradigm. Decades of progress will occur in months.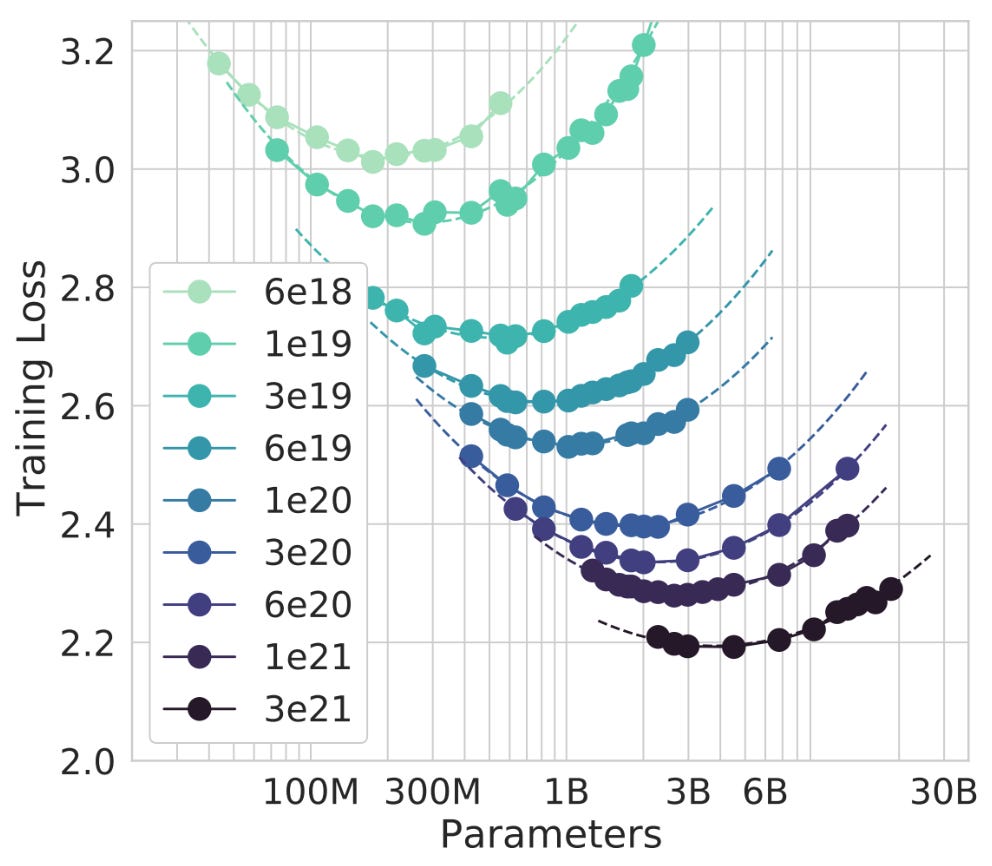
Pre-Training is About Data Above All Else
The three key insights from pre-training LLMs in the last 4 years all point to the importance of data.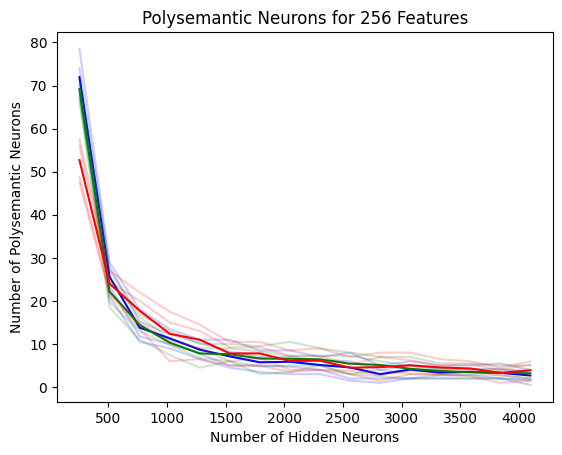
Polysemantic Neurons Can Occur Incidentally
Polysemantic neurons are an obstacle to interpreting AI. Even in over-parameterised models, they can arise incidentally. Accepted to BGPT & Re-Align @ ICLR ‘24.