Incidental Polysemanticity
Update: accepted to the Re-Align and BGPT workshops @ ICLR 2024!
One obstacle to interpreting neural networks is polysemanticity. This where a single neuron represents multiple features.
If there are more features than neurons, it might be "necessary" for the model to be polysemantic in order to represent everything. This is the notion of "superposition" from Elhage et al. (2022).
Of course, a clear solution would be to train a model large enough to have at least one neuron per feature. However, what we find in "What Causes Polysemanticity?" is that polysemanticity can happen "incidentally" in the training process, even if we have a large enough model.
Hypothesis
When we initialise a neural network, the weights are random. Some neurons will be more correlated with some features than other neurons, just by chance.
As training happens, the optimiser pushes the weights of those correlated neurons in the direction of the features, so that they can represent the features well. If there is pressure for sparsity, only one neuron will represent each feature.
Most likely, this is the neuron which was most correlated to the feature at initialisation. If it happened to be the most correlated neuron for multiple features, then it would end up representing multiple features.
In that case, we get polysemanticity "incidentally".
Experiments
To test this hypothesis, we consider the simplest possible setup: over-parameterised autoencoders similar to those in Elhage et al. (2022). That is:
where and , with . These models were trained on the standard basis vectors . To induce sparsity, we take two separate approaches: introducing regularisation for the model weights and adding noise after the hidden layer.
We find that:
- regularisation induces sparsity
- Some types of noise can induce sparisty
- The amount of incidental polysemanticity can be predicted
- It is due to the weight initialisations
Sparsity from Regularisation
Result 1: regularisation induces a winner-takes-all dynamic at a rate proportional to the regularisation parameter.
Loss with
Taking the th basis vector as the input, the output of the model is:
With regularisation, our loss function becomes:
where is the regularisation parameter.
Thus, gradient descent pushes us in the direction:
Forces for sparsity
We can split this into the three terms:
- Feature benefitThis is why we can use tied weights and , since it should push the th column of and the th row of to have dot product of , even if initialised as untied weights.: pushes to be unit length
- Interference: pushes to be orthogonal to other
- Regularisation: pushes non-zero to be sparse
The feature benefit and regularisation forces are in competition. Since the regularisation force has a constant value while the feature benefit force is proportional to the length of , the regularisation force will dominate for small and the feature benefit force will dominate for large .
Thus will be pushed to if it is below some threshold . Leaving the derivations for the paper, we find the net effect on sparsity is proportional to how far the weight is from this threshold:
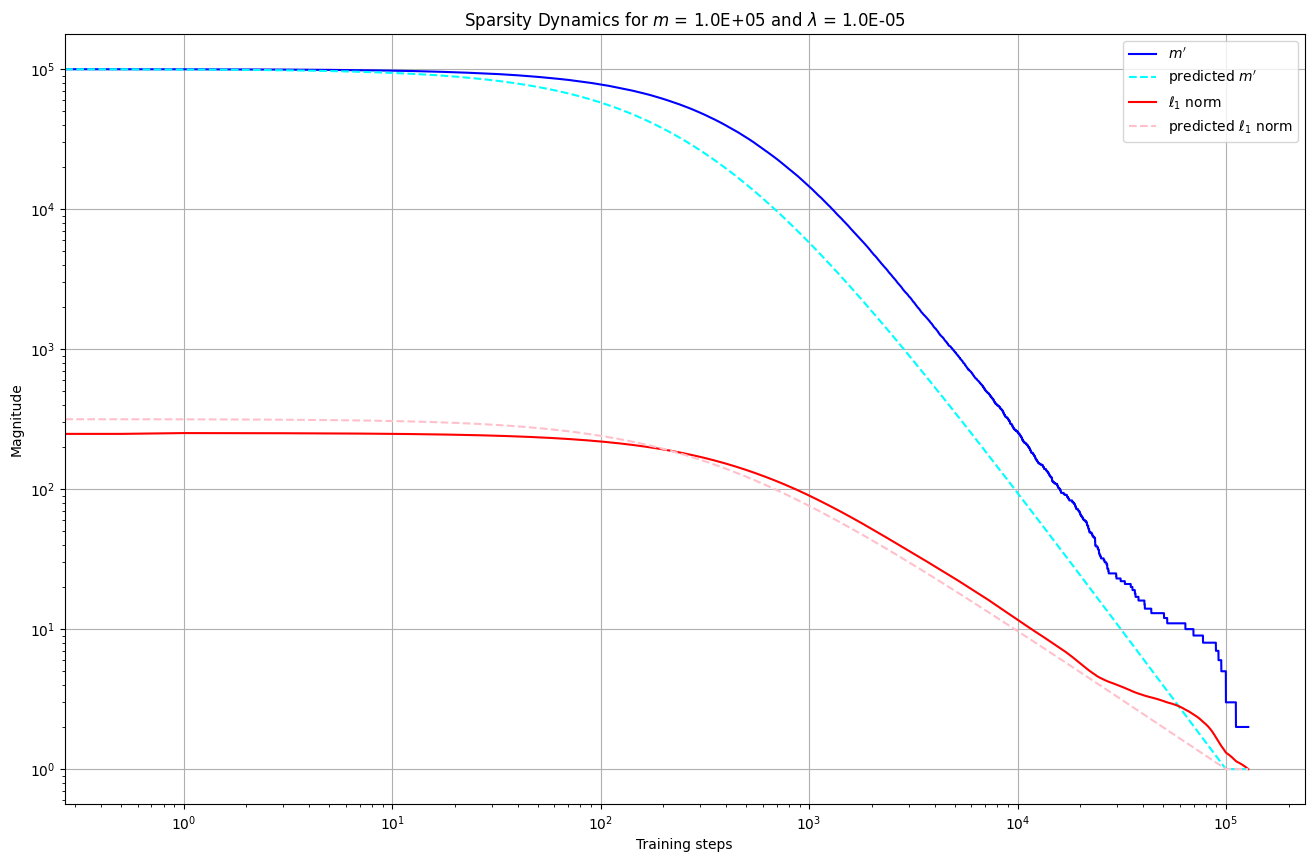
Speed of sparsification
In fact, we can quantify the speed at which sparsity is induced. Again, leaving the maths for the paper, it follows from above that the norm at time is inversely proportional to :
Since throughout training, the non-zero values at any particular point should have a magnitude of around , and so . Thus the weights should go from to as and as . This is exactly what we see:
Sparsity from Noise
Result 2: noise drawn from a distribution with excess kurtosis induces sparsity.
Implicit regularisation
In practice, we don't get sparsity in neural networks because of regularisation. A more realistic cause is via noise in the hidden layer, a la Bricken et al. (2023):
for and . Having removed the regularisation term, the loss is rotationally symmetric with respect to the hidden layer (excluding the noise). That means there is no privileged basis, and no particular reason for features to be represented by a single neuron, as opposed to a linear combination of features.
However, if we take the noise into account, we find that one term in the loss is:
where is the fourth moment of , and is the excess kurtosis.
Thus, when has negative excess kurtosis, this component of the loss will push to increase . Due to the constraint that from before, this incentivises for some and for .
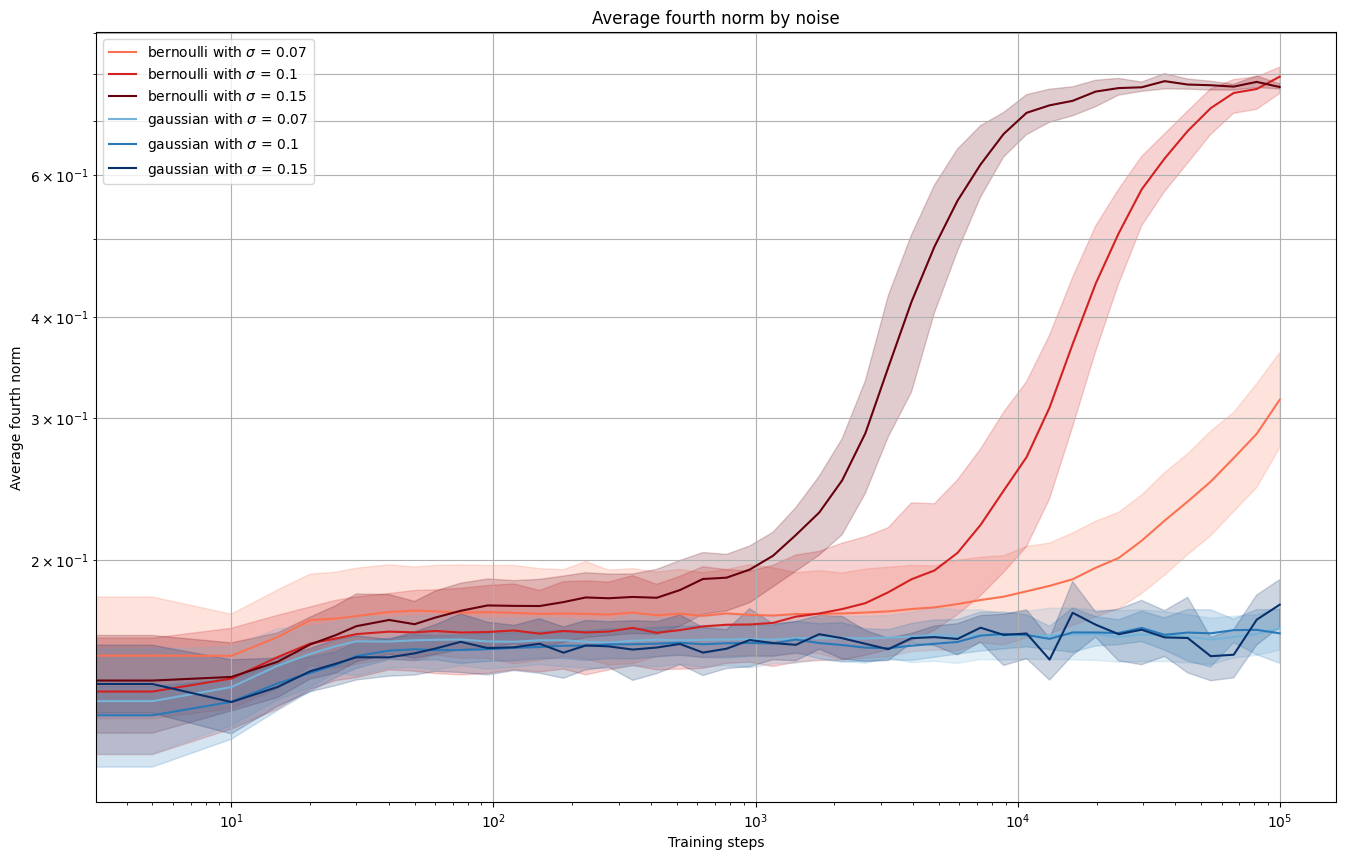
Bernoulli vs. Gaussian noise
Bernoulli noise of either has excess kurtosis of , while Gaussian noise has excess kurtosis of . Thus we would expect to see the former to induce sparsity (and a fourth norm of ), while the latter would not. As expected:
Counting Hypothesis
Result 3: the number of polysemantic neurons can be predicted by a simple combinatorial model.
Possible model solutions
Recall that the output of the autoencoder is:
That is, we would like and for .
One way to satisfy this is if equals the th standard basis vector . This is because will just be the identity matrix, and so .
However, when , we have another solution. Take and , and consider the following weight matrix:
We see that and , which still satisfying the constraints. This is a polysemantic solution!
Interference force
Knowing that it is possible, we can now ask why it occurs. One force we haven't considered in detail is the interference force:
up to constants.
This is only non-zero if the angle between and is less than . Thus, we can simplify by only considering its effect in the direction of . It has magnitude:
This means that the interference force should be weak at the start when are mean zero, and only kick in and share some non-zero coordinate . If and have the same sign, the interference force will push at least one to zero. Thus, we would only expect that polysemanticity occurs when they have the opposite sign, since the ReLU will zero out the negative term and they will maintain their non-zero value.
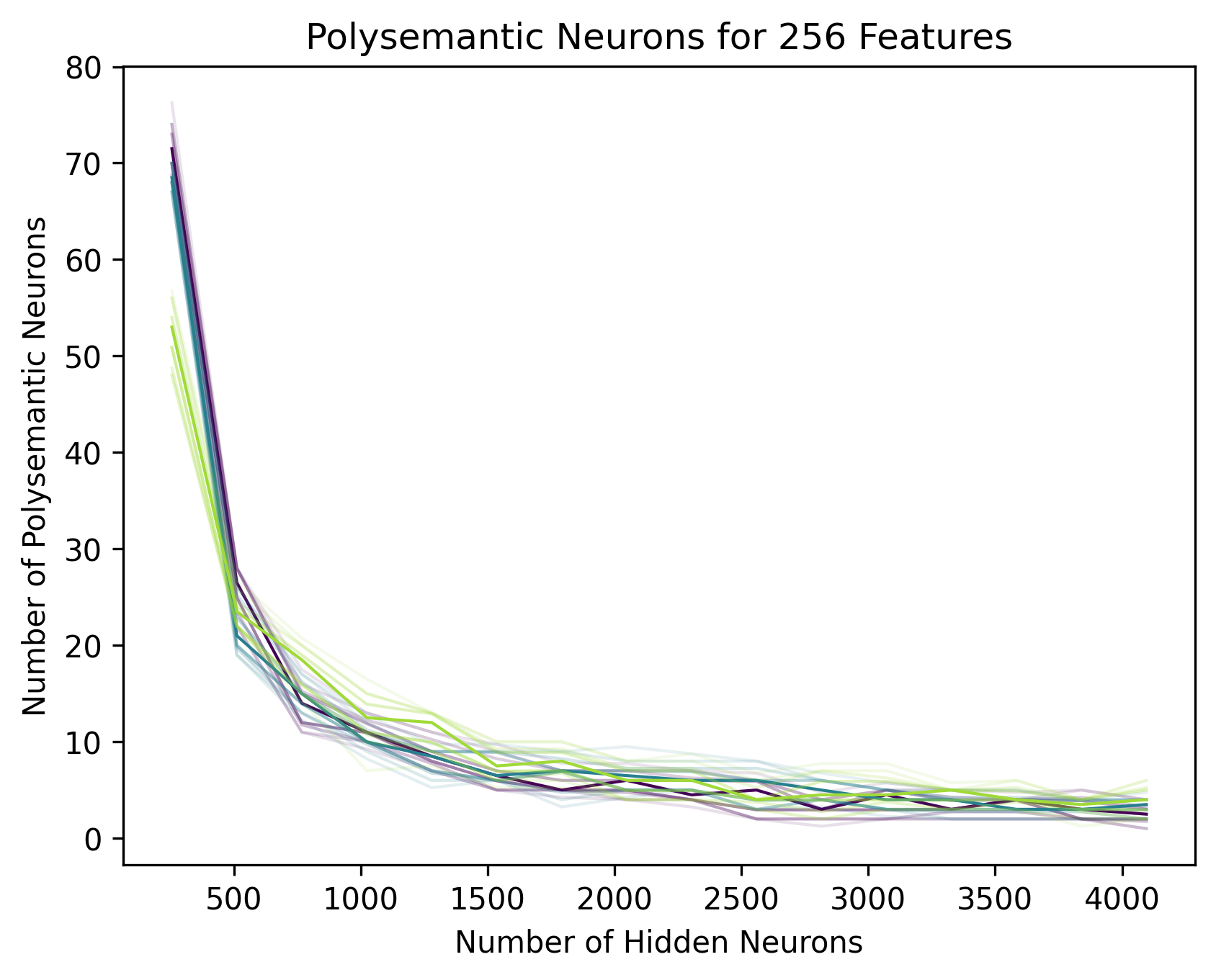
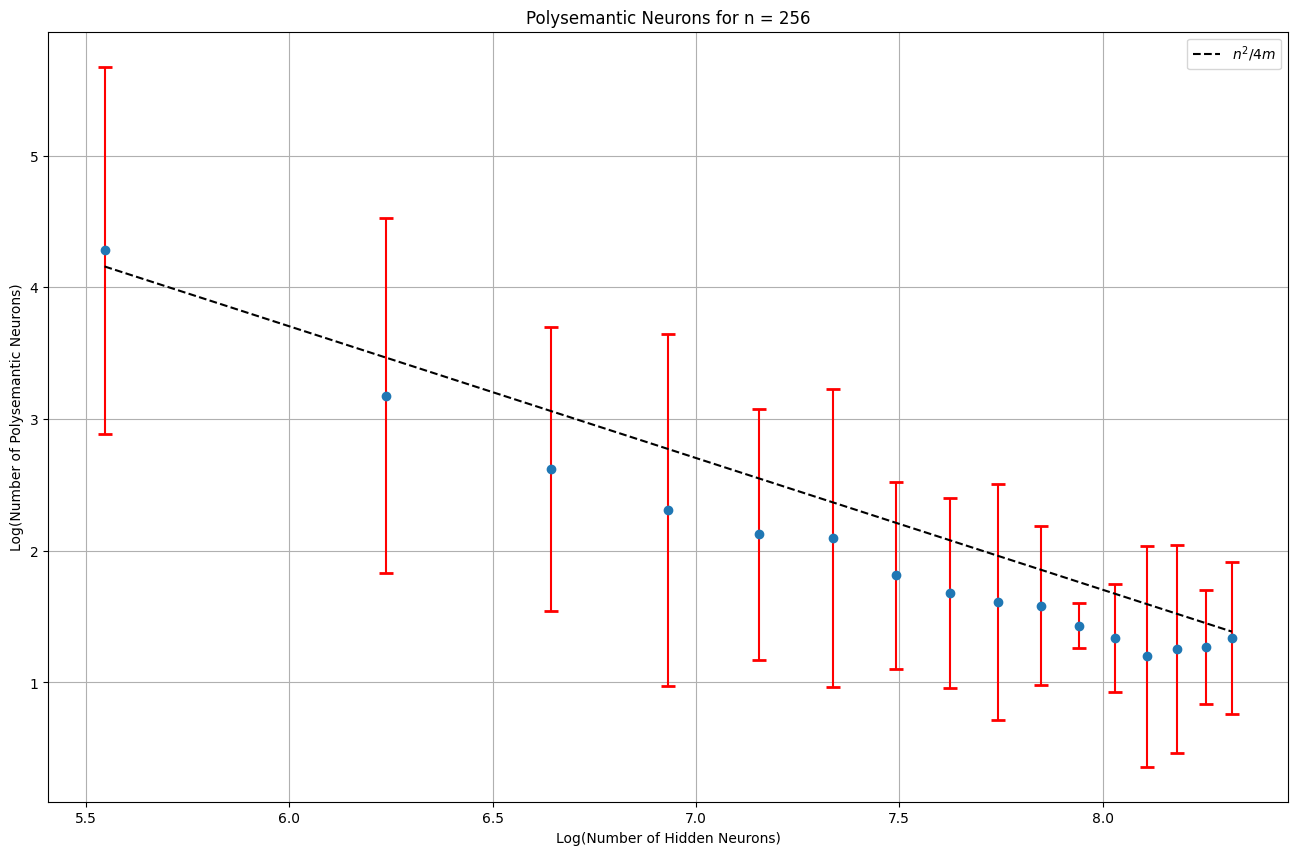
Balls and bins
With pairs of features, probability of the most significant neuron being the same for both and probability of them having the opposite sign, we would predict there to be polysemantic neurons, which we find:
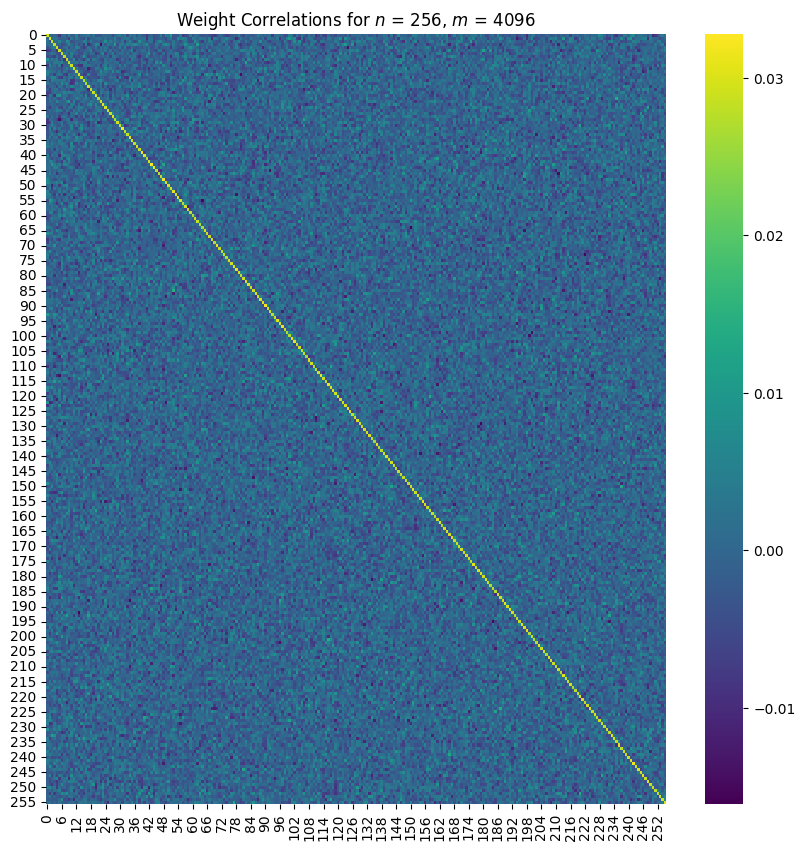
Initialisation Hypothesis
Result 4: polysemanticity occurs in models due to weight initialisations.
If initialisations were the cause of polysemanticity, the weights at the start of training should be correlated with the weights at the end. That is, the diagonals of should be larger than the off-diagonals. As predicted:
Future Work
The incidental polysemanticity we have discussed in our work is qualitatively different from necessary polysemanticity, because it arises from the learning dynamics inducing a privileged basis. Furthermore, the fact that it occurs all the way up to suggests that making the model larger may not solve the problem.
We look forward to future work which investigates this phenomenon in more fleshed-out settings, and which attempts to nudge the learning dynamics to stop it from occurring.
If you want to play with different configurations of our models or reproduce our plots, check out the code repository!